Dec
12
2017
12
2017 iMac Pro Review
There’s an old saying about money burning a hole in one’s pocket. Every once in a while, a product comes along that has a similar but reverse effect on me — it’s a product that’s so compelling, so exciting, so gorgeous to look at, that it causes my wallet to heat up and maybe even burst into flames. The new iMac Pro is one of those products.
Apple was kind enough to send me a 10-core iMac Pro with 128GB of memory for testing and evaluation purposes. I spent just short of a week running the machine through my typical workflows in aerospace engineering and software development, and also ran some benchmarks and tests. The iMac Pro made strong impressions on me in terms of performance and productivity. I’ll get into some of those results below, but I should mention that the iMac Pro also makes a strong visual impression. While it looks like other recent model 27” iMacs in shape and size, the iMac Pro is the first to come in Space Gray (with matching keyboard, mouse, and trackpad), and it’s a great look that says this machine means business. Sitting alongside my silver iMac, the iMac Pro lurked off to the side like a silent Darth Vader, just waiting to kick some ass.
Under the hood, it’s all business, with a 10-core Intel Xeon W-2155 CPU running at 3.0GHz (Turbo boost up to 4.5GHz). This is one of Intel’s recently-introduced workstation-class Xeon CPUs, meant to fill in a space between their consumer Core i9 processors and server-class Xeon Scalable CPUs within the extended Skylake family. If you want Core i9 performance with larger memory capability and more cores but don't need the all-out capabilities of a Xeon Scalable processor, Xeon W is the answer and it’s an ideal choice for a machine like the iMac Pro (which will offer 8-, 10-, 14-, and 18-core variants). The Xeon W also happens to be the first CPU in a Mac to support Intel’s AVX-512 vector processing, which increases the width of vector registers to 512 bits (up from 256 bits in AVX2) and doubles the number of vector registers to 32 per core (up from 16 in AVX2). I’ll talk more about that in a bit.
The 10-core CPU on my test unit has a single 13.8MB L3 cache and 1MB of L2 cache per core, and the machine is configured with 128GB of 2666MHz DDR4 ECC memory, a 2TB SSD (with hardware level line rate encryption), and an AMD Radeon Pro Vega 64 graphics chipset with 16GB of VRAM. Paired with a stunning 5120x2880 Retina "5K" display, the iMac Pro is a graphics powerhouse — I continually marveled at how crisp and clean everything was rendered with no apparent overhead or impact on performance. I’m used to choosing between performance or detail when visualizing complex 3D datasets, and the iMac Pro gives both. Even when just working in Xcode or a terminal window, the clarity and brightness of the screen made it really easy on the eyes.
Now onto some benchmarks, which are based on the use of computational fluid dynamics (CFD) for aerodynamic design and development. For this work, I used the TetrUSS CFD tools available from NASA, along with the ubiquitous NACA 0012 airfoil shape and the open geometry of the Common Research Model (CRM) transport aircraft.
A typical use of CFD is to evaluate the aerodynamic performance of aerospace vehicles like rockets and airplanes. The first step in this process is to create a mesh of the vehicle geometry from a CAD definition. This essentially lets us break the problem down into thousands or millions of small cells in which we numerically simulate the physics that govern flow. An analogous process is used in other areas of engineering analysis including structures and heat transfer. And though it doesn't involve simulation, OpenGL game programmers are well aware of the process of meshing a 3D object with triangles or quads in order to create a solid model that can react to lighting, shading, and other visual effects.
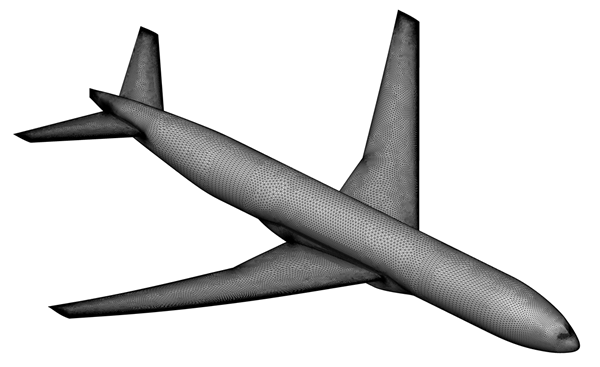
For this single-core benchmark, we'll look at generating the surface mesh on the CRM wing-body-tail configuration composed of 237,660 triangles:
{kind=link}
Timing results look very good for the iMac Pro (bottom bar in the graph below), which comes in fastest of the ten systems I’ve tested over the last five years by a notable margin.

Another key part of the CFD process is the actual numerical simulation, where we compute flow on the mesh. Often, these simulations are run on supercomputer clusters, using anywhere from 500 to 2000 cores or more, sometimes over a period of days or weeks. Smaller cases can be run on multi-core desktop computers like the iMac Pro, especially among small business users and folks in academia (normally the size of cases will be limited by memory, but that won’t be a problem with 128GB on the iMac Pro — that can easily handle most cases of practical interest).
Unlike mesh generation, the flow simulation is very amenable to parallel processing and makes for a very good multi-core benchmark. Here, we compute flow around a NACA 0012 airfoil. Results are plotted to show the computation time (in seconds) as a function of the number of cores used, ranging from 1,2,3,4.... up to 12 cores on some machines. Among the same set of computers compared above, the iMac Pro (red curve on the bottom) again fares very well, coming in with notably lower times all the way up to 10 cores:
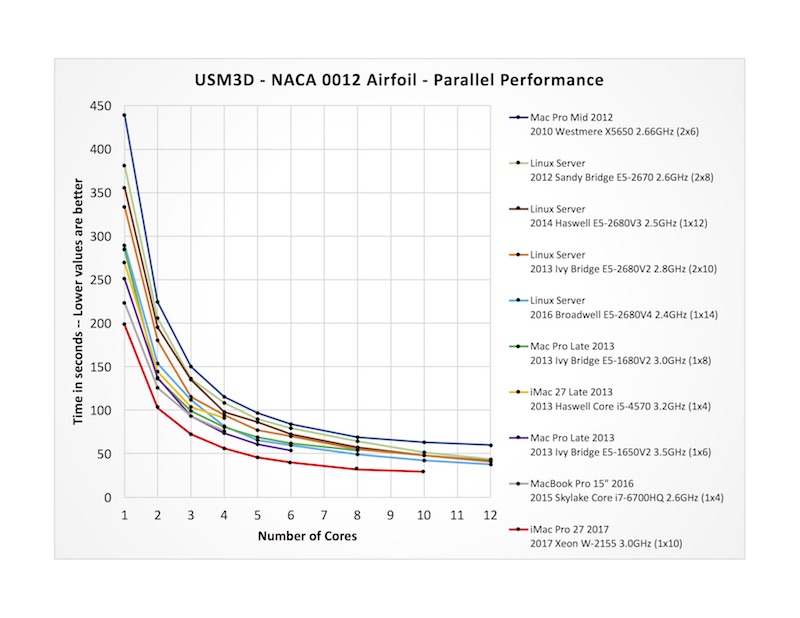
I also looked at scaling performance, which is interesting and tells a lot about a computer’s architecture. Contrary to what many people expect, there isn’t always a perfect gain when you throw more cores at a problem — at some point the cores start to compete for various system resources like memory and disk, and performance begins to flatten out as you can see in the timing chart above. The chart below shows this more clearly by computing the multi-core speedup (=single-core time divided by multi-core time) for each computer tested. For reference, an ideal trend is shown with a dashed line. In this case, the iMac Pro (red curve) sits pretty much in line with the pack, approaching a 6.7X gain when using all 10 cores. It would have been interesting to run the same test with an 18-core iMac Pro, but alas, they won’t ship until January.

Another important, albeit less quantitative benchmark relevant to me is software development. I tend to do most of my engineering and CFD-related software development working in a terminal with C and Fortran compilers, but for my iOS and Mac app development work I spend a lot of time in Xcode. A lot. A few weeks ago I was debugging an especially nasty MapKit tile rendering bug while racing to get my augmented reality app Theodolite ready for iPhone X, and I am pretty sure I clicked Xcode’s build/run button thousands of times over a couple days (at least it felt that way). When you get into an intense development or debug cycle that involves a lot of compiles, saving fractions of seconds here and there adds up and can give you extra hours in a day. This is one area where the 10-core iMac Pro shines when combined with Xcode’s ability to automatically take advantage of multiple cores to compile multiple source files simultaneously.
Most of my apps have around 20,000-30,000 lines of code spread out over 80-120 source files (mostly Obj-C and C with a teeny amount of Swift mixed in). There are so many variables that go into compile performance that it’s hard to come up with a benchmark that is universally relevant, so I’ll simply note that I saw reductions in compile time of between 30-60% while working on apps when I compared the iMac Pro to my 2016 MacBook Pro and 2013 iMac. If you’re developing for iOS you’ll still be subject to the bottleneck of installing and launching an app on the simulator or a device, but when developing for the Mac this makes a pretty noticeable improvement in repetitive code-compile-test cycles.
I’ve had a long infatuation with vectorization, dating back to Cray supercomputers in the 1990s and AltiVec on PowerMac G4 and G5 hardware in the 2000s (for a flashback, you can read my 2002 O’Reilly article on AltiVec here). So I was pretty excited to hear that the iMac Pro has made a big leap in vector processing.
Vectorization is a form of single-instruction-multiple-data (SIMD) processing, where a processor is able to perform operations on multiple data elements within a “vector” simultaneously. In contrast, typical “scalar” code operates on one data element at a time. A classic example of scalar code is shown in the loop below, where we add elements of array "a" to elements of array "b" and store the result in array "c":
for (i=0;i<N;i++) {
c[i]=a[i]+b[i];
}
As we loop through the i index, we handle one element of data at a time. If you’re a nerd, you’ll know that each pass through the loop requires two loads, an add, and a store — four operations — so we have a total of 4*N operations in the scalar loop. Now, in the case of the AVX-512 vector processor on each core of the iMac Pro’s CPU, we can form vectors that hold sixteen single-precision (32-bit) floats or eight double-precision (64-bit) floats (or equivalents when using integers). If we assume the arrays in our example are double-precision, the equivalent vector loop using AVX-512 vector instructions looks like:
for (i=0;i<N;i=i+8) {
__m512d a_vec = _mm512_load_pd(&a[i]);
__m512d b_vec = _mm512_load_pd(&b[i]);
__m512d c_vec = _mm512_add_pd(a_vec,b_vec);
_mm512_store_pd(&c[i],c_vec);
}
Again, we have two loads, an add, and a store per pass through the loop, but since we’re operating on vectors that each hold eight doubles, we increment our loop by 8 each time, and the total number of operations is 4*N/8 — an eight-fold reduction!
You’d be right to expect an 8X increase in performance here, but in reality that’s a bit theoretical and in the real world it’s going to be less. How much less depends on a lot of things, like the data size, whether it fits in the various caches or spills onto RAM, and so on. But in this case, picking N=512, the results are pretty good, with a 5.2X speedup from AVX-512. For comparison, I also included AVX2 results, using 256-bit wide vectors that can hold 4 doubles at a time. This nets a 3.0X speedup. And though I won't get into the coding details here, running the same tests using single-precision floats nets speedups of 10.1X for AVX-512 and 6.3X for AVX2.
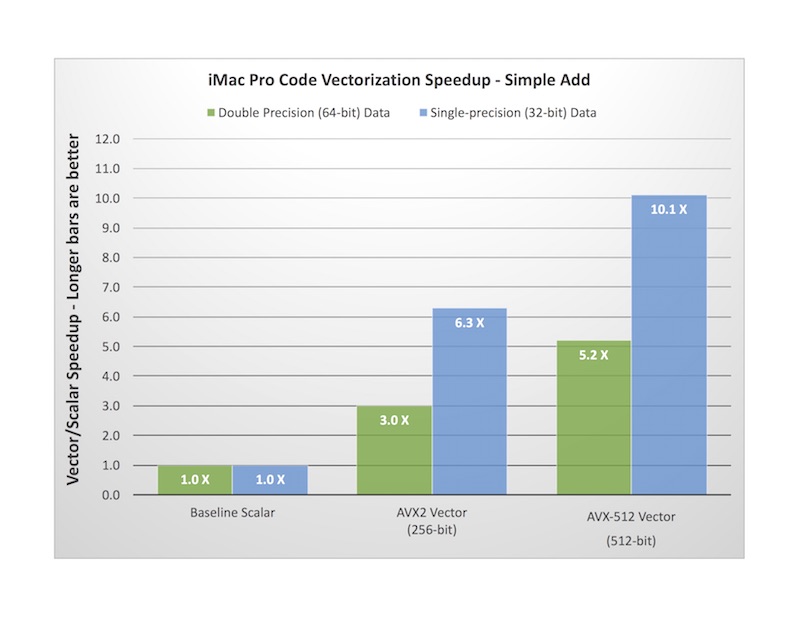
It’s important to note that I used intrinsic AVX-512 vector instructions in the code example above for the purpose of illustration (and also to get very explicit control for benchmarking). In reality, modern compilers are very good about auto-vectorizing eligible scalar loops, and in most cases, you don’t need to do anything other than pick a higher level of optimization (typically —O2 or —O3) and specify the correct architecture and/or instruction set flags. Another option is to link against vector-optimized libraries. Intel's Math Kernel Library (MKL) is highly optimized for AVX-512, and I am told Apple's Accelerate framework has also been optimized to take advantage of AVX-512 (with more improvements to come).
An obvious question, not directly answered by my benchmarks here, is how the iMac Pro compares to a recent model standard iMac for performance. The closest direct comparison here is my Late 2013 iMac, but it’s several generations behind. That said, I was able to get some limited data on a 2017 iMac with a 4.2GHz quad-core Core i7 processor, and while that machine is slightly faster than the iMac Pro on single-core, the performance flattens out with more cores and the advantage is gone by 4-cores. From 4 to 10 cores, the iMac Pro runs away. Or if you can take advantage of AVX-512 (not available on a standard iMac) the iMac Pro runs away. This sort of reinforces one of the main advantages of the iMac Pro — moving to a workstation class CPU gives access to more cores, advanced processing features, and a bigger, more scalable, performance envelope than you can get in a standard iMac. Other key advantages are memory capacity and graphics capability. If your work benefits from any of these things, then the iMac Pro is the natural choice.
As I write this, Apple hasn’t released full pricing for the iMac Pro line other than noting that a base 8-core model with 32GB memory, 1TB SSD, and a Vega Pro 56 graphics chipset will start at $4999. The nearest comparable shipping 27” iMac I configured was $3699 but with a greatly inferior CPU and graphics chipset, four fewer cores, and other disadvantages across the board. So in that context, spending another $1300 to get into an iMac Pro is a no brainer. It will be interesting to see how the higher end models price out, especially the 18-core model, but if the trend is in line with the base model, this will be quite a deal for people that are ready to spend money on a true workstation-class Mac. Just be careful that your wallet doesn’t catch on fire.

The original, indispensable, pioneering AR viewfinder.
Where will you take it on your next adventure?